Flame graphs are the most powerful visualization tool for finding performance bottlenecks instantly. When your API is slow, flame graphs reveal whether the bottleneck is database queries, external APIs, or CPU-intensive code—no guesswork required. This comprehensive guide teaches you how to read flame graphs, identify common performance patterns like N+1 queries, and optimize your application based on visual performance data.
Table of Contents
- What is a Flame Graph?
- Reading a Flame Graph: The Basics
- Real-World Example: Finding the Bottleneck
- Common Patterns to Look For
- How to Generate Flame Graphs
- Optimizing Based on Flame Graphs
- Flame Graphs vs. Traditional Profiling
- Advanced Tips
- Frequently Asked Questions
- Try It Yourself
What is a Flame Graph?
A flame graph is a visual representation of your code’s execution. Imagine taking a snapshot of your running application thousands of times per second and stacking the results. The result shows:
- Width = How much time was spent (wider = slower)
- Height = Call stack depth (how nested the function calls are)
- Color = Different services or function types
At a glance, you can see which functions consume the most time – no log diving required.
Reading a Flame Graph: The Basics
Let’s break down what you’re looking at:
The X-Axis (Width)
Wider boxes = more time spent. If a function takes up 60% of the width, it consumed 60% of your request time. Simple as that.
The Y-Axis (Height)
Each layer represents a function call. The bottom is your entry point (e.g., HTTP request handler). Each layer above shows functions called within functions.
Colors
Different colors help you quickly identify:
- Blue = Database queries
- Purple = External API calls
- Green = Your application code
- Red = Framework/library code
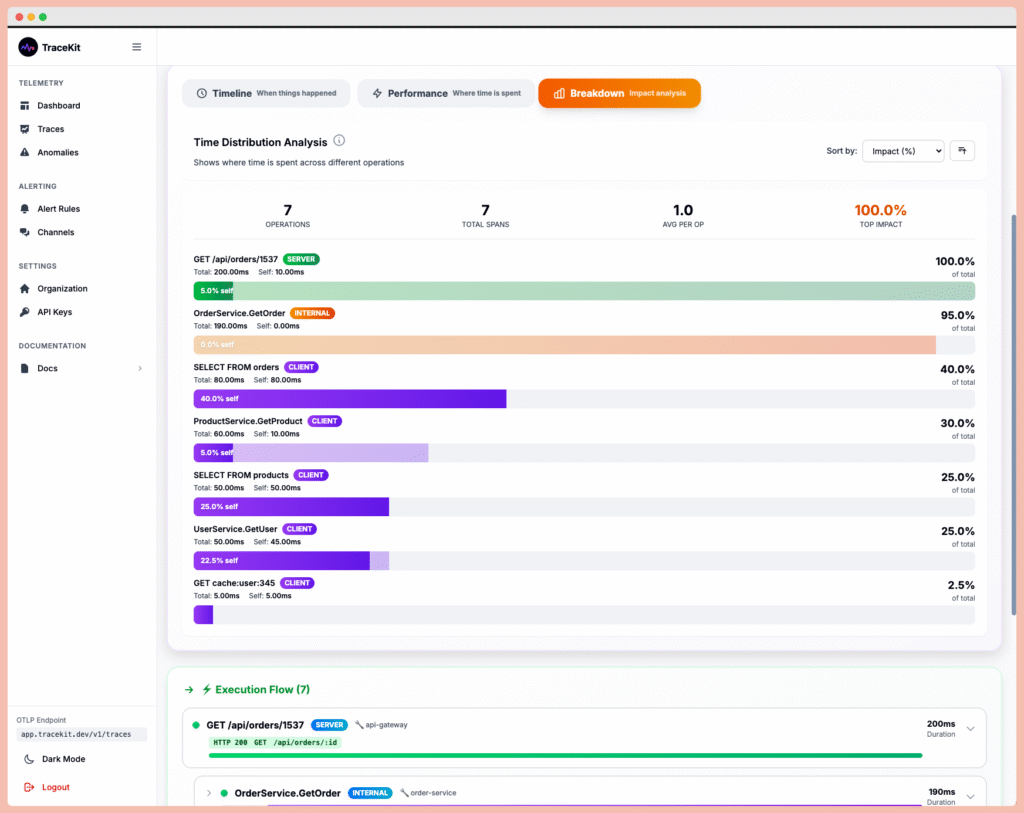
Real-World Example: Finding the Bottleneck
A SaaS company complained their API was taking 2 seconds per request. Logs showed “database query slow” but optimizing the database didn’t help.
Looking at the flame graph revealed the truth:
- The main request took 2000ms
- Database queries took only 200ms (10%)
- A single function “generatePDF()” took 1600ms (80%!)
- They were generating PDFs synchronously on every request
Solution: Move PDF generation to a background job. Request time dropped from 2000ms to 300ms.
The flame graph made it obvious in 30 seconds.
Common Patterns to Look For
1. The “Wide Tower”
One function dominating the entire width = clear bottleneck. Fix this first.
┌──────────────────────────────┐
│ slowDatabaseQuery() │ ← 80% of time
└──────────────────────────────┘
2. The “Coral Reef”
Many small functions at the same level = N+1 query problem. You’re making hundreds of small queries instead of one big query.
┌─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┐
│ │ │ │ │ │ │ │ │ │ │ │ │ │ │ ← 200 tiny queries
└─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┘
3. The “Deep Stack”
Very tall stacks = excessive function calls or recursion. Might indicate over-abstraction or inefficient algorithms.
How to Generate Flame Graphs
With TraceKit, flame graphs are automatic. Every trace includes a flame graph view:
- Click any trace in your dashboard
- Switch to the “Flame Graph” tab
- Click any box to zoom in
- Hover for exact timing details
No configuration needed – it just works.
Optimizing Based on Flame Graphs
Database Bottlenecks
See a wide blue box? Database query is slow. Options:
- Add indexes to speed up queries
- Cache frequently accessed data
- Use eager loading to avoid N+1 queries
- Optimize the SQL query itself
External API Calls
See a wide purple box? External API is slow. Options:
- Call APIs in parallel instead of sequential
- Cache API responses
- Add timeouts to fail fast
- Move to background jobs if possible
Application Code
See a wide green box? Your code is slow. Options:
- Profile the function to find loops or inefficiencies
- Use better algorithms (O(n²) → O(n log n))
- Move heavy computation to background jobs
- Add caching for expensive calculations
Flame Graphs vs. Traditional Profiling
| Traditional Profiling | Flame Graphs |
|---|---|
| Requires code changes | Automatic with tracing |
| Only works locally | Works in production |
| Shows averages | Shows specific requests |
| Text-based output | Visual, interactive |
| Hard to share | Click to share link |
Advanced Tips
Compare Before/After
Generate flame graphs before and after optimization. The visual difference makes it easy to verify improvements and share results with your team.
Filter by Timeframe
Look at flame graphs during peak vs. off-peak hours. Different bottlenecks might appear under load.
Group by Service
In microservices, group flame graphs by service to see which services are the bottlenecks in distributed requests.
Frequently Asked Questions (FAQ)
What is a flame graph?
A flame graph is a visualization that shows where your code spends time during execution. The width of each box represents how much time was spent in that function, the height shows the call stack depth, and colors help identify different types of operations (database, API calls, application code). Flame graphs make performance bottlenecks immediately visible.
How do you read a flame graph?
To read a flame graph, look at the width to find time-consuming functions (wider = slower), follow the height to see the call hierarchy, and use colors to identify operation types. Wide boxes at any level indicate bottlenecks. Many small boxes at the same level suggest N+1 query problems. Tall stacks indicate deep function nesting or recursion.
What do colors mean in flame graphs?
In flame graphs, colors typically represent different operation types: blue for database queries, purple for external API calls, green for application code, and red for framework/library code. Some tools use random colors for visual separation while others use semantic colors to make different operation types instantly recognizable.
How do flame graphs help with performance optimization?
Flame graphs help optimize performance by visually highlighting bottlenecks, making it obvious which functions consume the most time. They reveal N+1 query patterns (many small database calls), show slow external API dependencies, identify CPU-intensive code sections, and help compare performance before and after optimization changes.
Can I use flame graphs in production?
Yes, flame graphs can be used in production with distributed tracing tools that have minimal performance overhead. Production flame graphs are valuable because they show real-world performance with actual data volumes and traffic patterns. Modern APM solutions capture flame graph data automatically without requiring code changes.
Try It Yourself
Want to see flame graphs in action?
- Try the demo to explore real flame graphs from production systems
- Start a free trial and generate flame graphs from your own application
- Read the docs for framework-specific guides (Laravel, Express, Spring Boot)
Flame graphs turn performance debugging from guesswork into certainty. The bottleneck is always obvious.
Have questions about flame graphs? Try TraceKit free and see your application’s flame graphs in minutes. Check our documentation for more performance optimization tips.